LMDeploy 多卡张量并行优化指南
技术调优探讨
1
帖子
1
发布者
42
浏览
1
关注中
-
** LMDeploy 部署后为充分发挥软硬件性能,可按自身需求组合以下优化项:**
1、显存均衡
a、pip安装部署的可以按照LMDeploy官方回复的解决方法
https://github.com/InternLM/lmdeploy/issues/3518
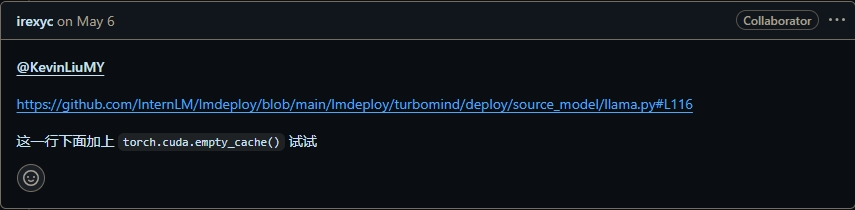
使用下面命令按实际文件路径修改,sed -i \ -e '/def readers(self):/,/def model_info(self):/ {' \ -e '/yield i, reader/ {' \ -e 'a \ torch.cuda.empty_cache()' \ -e '}' \ -e '}' \ /opt/lmdeploy/lmdeploy/turbomind/deploy/source_model/llama.pyb、使用docker,可以dockerfile 直接生成修改好的镜像,dockerfile如下:
# 使用基础镜像 FROM openmmlab/lmdeploy # 设置工作目录 WORKDIR /opt/lmdeploy/lmdeploy/turbomind/deploy/source_model/ # 执行 sed 命令插入代码并安装 modelscope(合并层优化) RUN sed -i \ -e '/def readers(self):/,/def model_info(self):/ {' \ -e '/yield i, reader/ a \ torch.cuda.empty_cache()' \ -e '}' \ llama.py && \ pip install modelscopecd进入dockerfile所在目录,生成显存均衡本地镜像
docker build --no-cache -t lmdeploy-0.9-mod .2、LMDeploy长上下文yarn配置优化参考
模型config.json
"rope_scaling": null,这部分修改为
"rope_scaling": { "type": "yarn", "factor": 4.0, "original_max_position_embeddings": 32768 },启动参数添加
--session-len 131072实际可用上下文还受显存大小影响,LMDeploy启动日志中会有如
`session_len` truncated to xxxxxx可以结合以下三个参数充分利用现有显存
--cache-max-entry-count 推荐从0.5-0.7开始逐步调整,确保启动完成后剩余显存大于512-1024M即为稳定最大值 --max-batch-size 推荐32,显存最够可以64甚至128(数值调小可适当增加上下文) --quant-policy 推荐8,显存足够可以删除该启动参数(8比无该参数可增加接近一倍上下文)3、LMDeploy T10多卡参考极限上下文参数
双卡T10 LMDeploy TP=2 运行Qwen3-32B-AWQ 极限稳定上下文为70k
启动关键参数为--cache-max-entry-count 0.80 --max-batch-size 32 --quant-policy 8 --session-len 131072四卡T10 LMDeploy TP=4 运行Qwen3-32B-AWQ 稳定上下文128k是最小参数为
--cache-max-entry-count 0.50 --max-batch-size 64 --quant-policy 8 --session-len 131072四卡T10 LMDeploy TP=4 同时运行Qwen3-32B-AWQ 96k 和Qwen3-30B-A3B-AWQ 39k 稳定参数为
Qwen3-32B-AWQ 96k--cache-max-entry-count 0.3 --max-batch-size 64 --quant-policy 8 --session-len 131072Qwen3-30B-A3B-AWQ 39k
--cache-max-entry-count 0.37 --max-batch-size 32 --quant-policy 8